Automattic, the company behind WordPress and Tumblr, is planning discussions to monetize user content by selling its data to artificial intelligence companies, including MidJourney and OpenAI. Data from the blogging platforms Tumblr and WordPress.com will be used to train AI models.
While the details of the transaction are still unclear, this news has raised concerns among users regarding the potential misuse of their private content on the two blogging platforms. Additionally, 404 Media suggests that internal conflicts have arisen within Automattic as the collected content includes private data that was not intended for retention within the company.
In response to the negative reactions, Automattic plans to introduce a new feature that will allow users to opt out of sharing their data for AI training. The company, in a blog post, reaffirms its commitment to providing Tumblr and WordPress users with greater control over their content. It mentions the launch of a setting to "discourage exploration by AI companies," explaining that top AI exploration platforms are blocked by default.
The issue of using blog content by companies developing AI models is not limited to platforms managed by Automattic. Both OpenAI and Google use crawler robots to gather information from all websites to train artificial intelligence models. The process is similar to data collection by search engines.
How can you block OpenAI and Gemini (Bard) from fetching data from your blog?
If you own a blog or website and do not want its data to be used for training OpenAI and Gemini artificial intelligence models, you can block access to robots (crawlers) to the content. This restriction can be implemented through the robots.txt file.
OpenAI Crawlers
User-agent: GPTBot
Disallow: /Gemini Crawlers
User-agent: Google-Extended
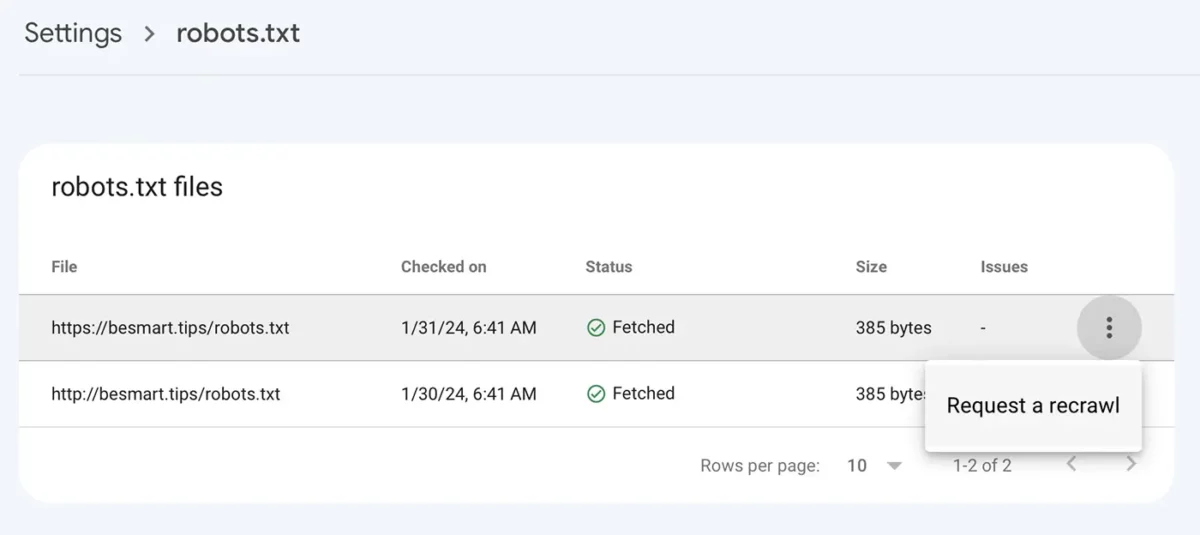
Disallow: /After saving the robots.txt file with the new lines, go to Google Console at: Settings > robots.txt > click on the menu with the three dots, click "Request a recrawl."
Related: GPT-5 and the new web crawler GPTBot developed by OpenAI.
For Tumblr and WordPress users, access to data retrieval from blogs by OpenAI or other artificial intelligence development companies can be blocked through tools provided by Automattic.